浅谈Raft
raft是什么
http://nil.csail.mit.edu/6.824/2021/papers/raft-extended.pdf
Raft is a consensus algorithm for managing a replicated log.
为什么要有raft,或者说,为什么要有consensus algorithm
前传:Single point of failure
很多分布式系统都是master-slave。这里master就是一个single point of failure。这时要有一个fail-over机制,也就是一个slave要变成master。
核心问题:Split brain
slave咋知道master fail了呢?
slave只知道master不发送信息了(比如不回心跳了)。有可能master死了,也有可能只是网络拉了。
所以就两难了。如果master活着,那slave不应该成为新的master;反之,slave应该成为新的master。但这就很难判断。
解决:Consensus
所以要有consensus。常常是多数投票(quorum),比如raft就是。
Raft的基本想法
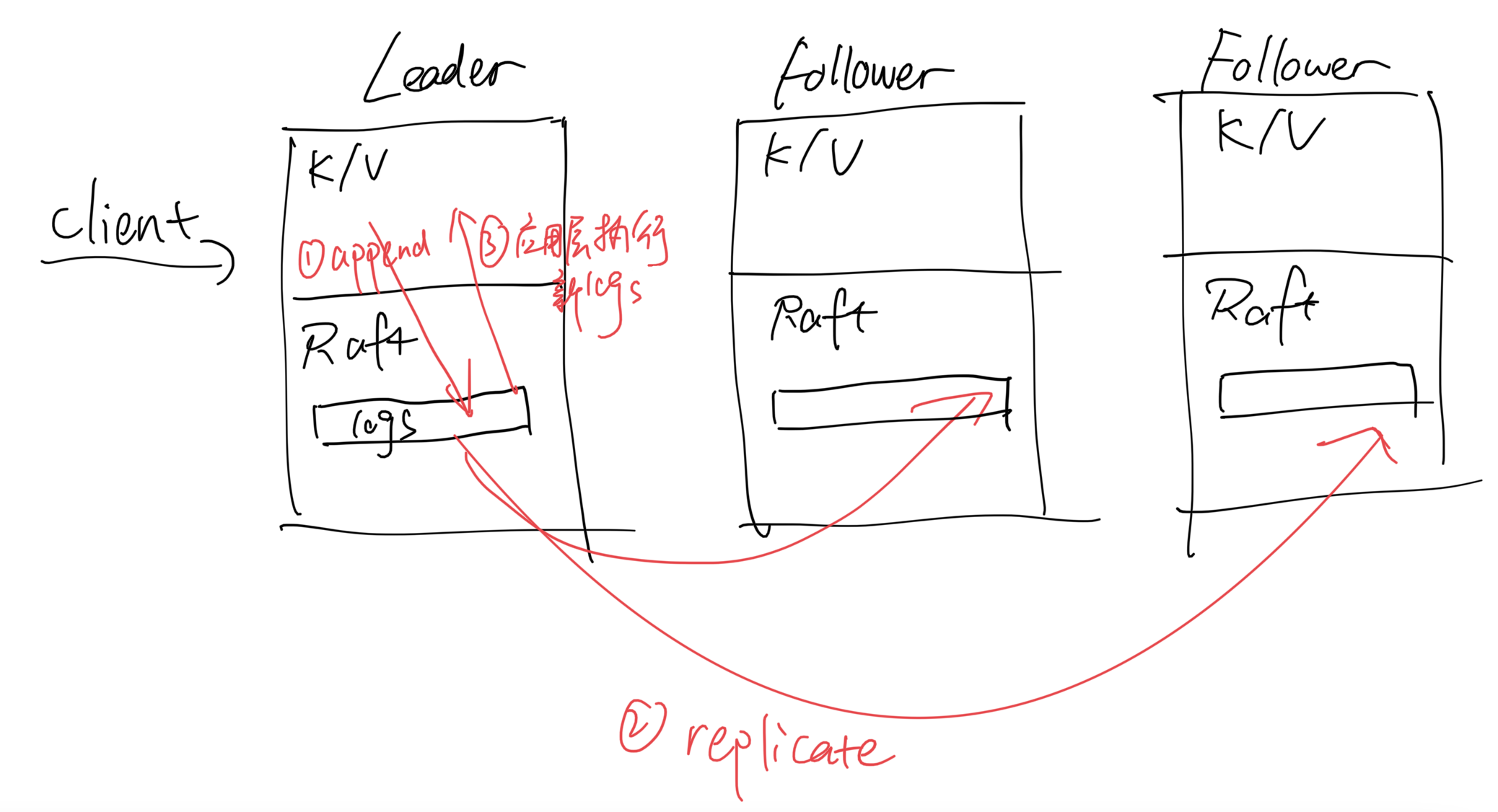
假设应用层是Master-slave架构,raft提供一个类似Replicated WAL(自创词)的日志服务。(思考MySql binlog,不过binlog貌似不是write-ahead的)
Client只与Leader互动。更改会先体现在raft的log上。当raft认为该log已经安全地被复制(这条log entry无论如何都不会消失了)的时候,才会将日志commit,并且返回应用层执行相应的日志内容。
Election
每个服务器都会有一个election timeout。如果这段时间内没有收到信息(当然,是从leader发来的信息)的话就发起一次election。
唯一要注意的点是:如果很多机器同时timeout并且start election,可能会无限平票。所以一般在timeout上加一个randomization,减少冲突。
Log and Term
必看!
记住,这一切都为了保证一点:
commit了的entries,不管怎么样都不能消失。
反之,对于没有commit的,怎么样都行。
Commit
当leader发出AppendLogRPC,并且majority表示自己收到了,那么就commit。Raft保证commit了的值必然会最终体现在所有服务器上。
Term
这可能是我一开始最搞不清楚的地方。
举个例子,请说出这张图中哪些log不可能出现:
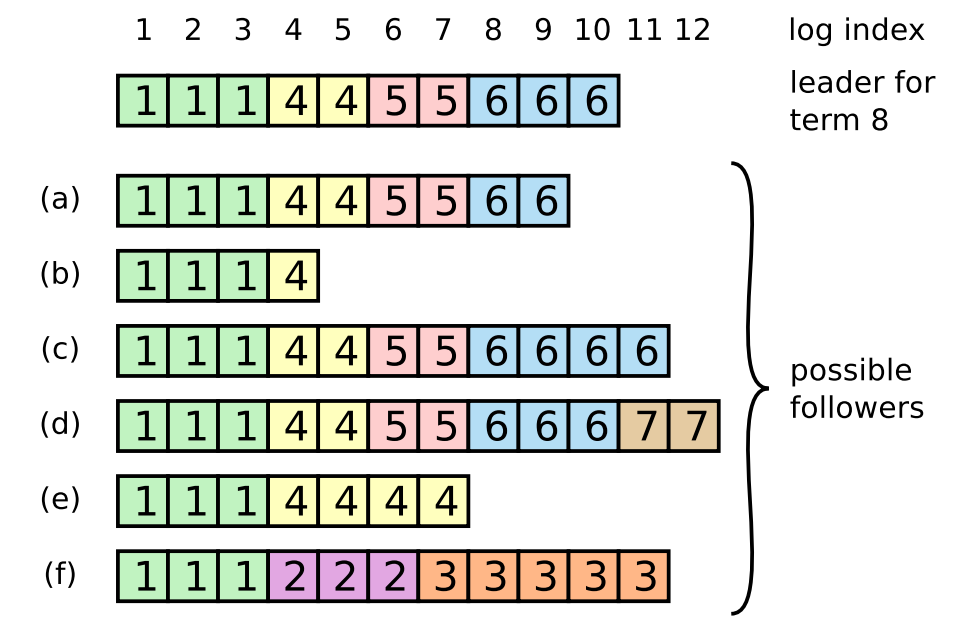
答案是都有可能出现,因为都没有违反对于log的restriction(见下)。
那么这里哪些服务器可能会被选为leader呢?答案是(a)(c)(d)。因为只有它们可能包含所有已经commit的entries。
Election Restrictions & Log Restrictions
1. 如果要选一人当leader,它必须拥有所有committed entries。
这是为了保证在日志永远单向流动(leader -> follower)的情况下,leader拥有所有committed entries。
2. 如果一人收到的信息中包含Term值比它自己最大的还大,它必须马上转为follower。
因为显然,此时另一人Term比自己大的话,说明另一个人成为leader严格比自己更好,即他更可能拥有所有committed的entries。
3. 如果另一人发起投票且最新的日志没有自己新,那么不为它投票。
”日志没有自己新“的意思是:别人最后一条日志Term < 自己最后一条日志Term;或者 别人最后一条日志Term == 自己最后一条日志Term 但自己日志更长。
和上一条相反,说明另一人严格比自己拉胯。不投票。
情景分析
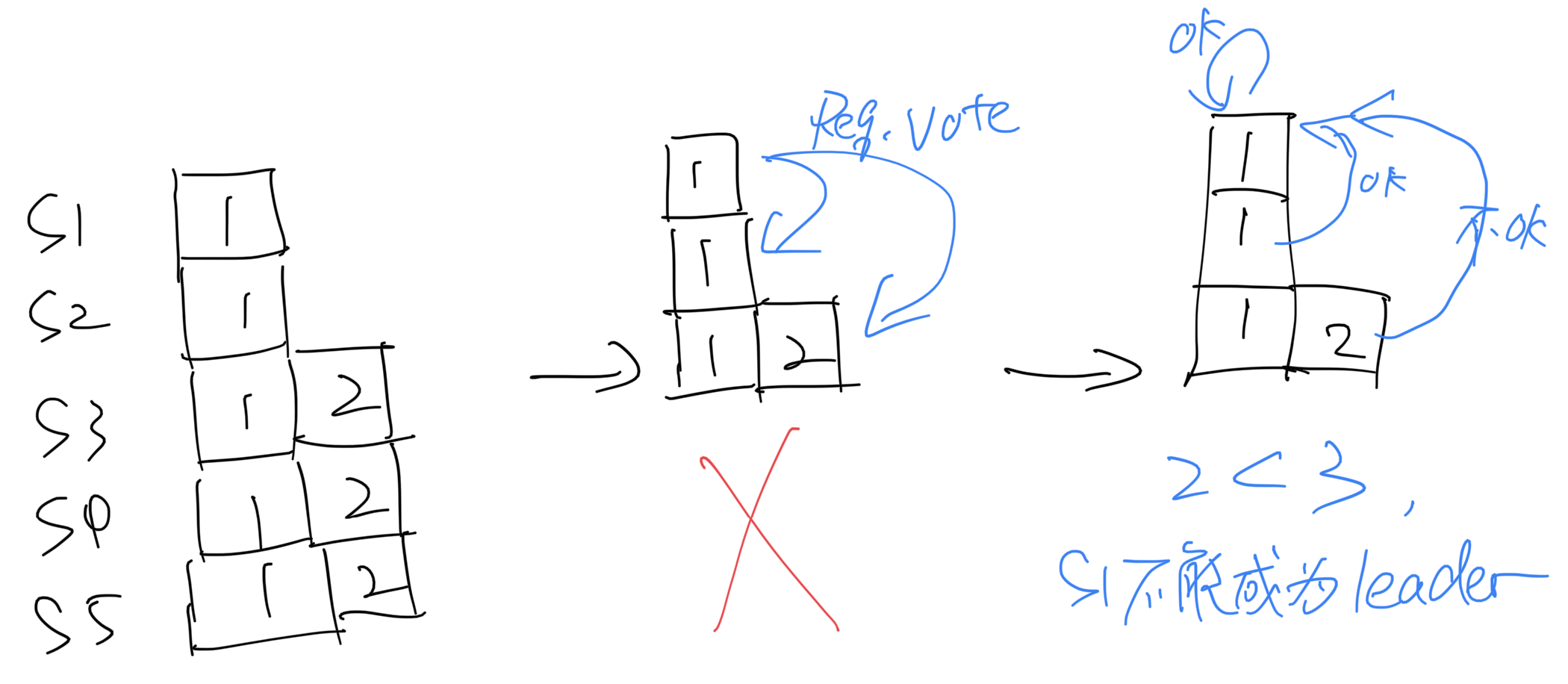
此例中,由于第3条restriction,S1不能成为leader。如果S1成为了leader,那么commit了的“2”就会被覆盖。
另一个好处是:收到S3返回的term之后,根据第2条restriction,S1会自动转为follower,加速了S3成为新leader的过程。
这个例子可以看出”必须复制到majority才能commit“这点的好处。当committed了的值出现在majority上,minority服务器不管怎么样都不可能成为leader。
Election之后
leader会把自己的意志强加给followers(危)。
就是强迫followers的日志变得和自己一毛一样。不一样的部分全扔了,改成和我一样。
强迫的过程
维护nextIndex[]和matchIndex[]。
nextIndex[i]: 下一个要发送给服务器i的日志index。
向服务器i发送从nextIndex[i]开始的全量log。设
prevIndex = nextIndex[i] - 1
如果(Leader的Log)[prevIndex].term与(服务器i的Log)[prevIndex].term不一样,说明服务器i还是太旧了。操作:nextIndex[i] -= 1,然后重复。
matchIndex[i]: 服务器i上已知复制成功了的最大日志index。这主要是为leader中有”不知道有没有commit“的entry准备的。
比如还是这幅图,S3可能只是收到了”2“,但没人告诉它commit了。所以”2“到底有没有commit?
如果在它疑惑的时候S4 S5重连了,S3一看,matchIndex[4] = matchIndex[5] = 2。ok,看来”2“已经在majority上了。所以”2“应该被commit。
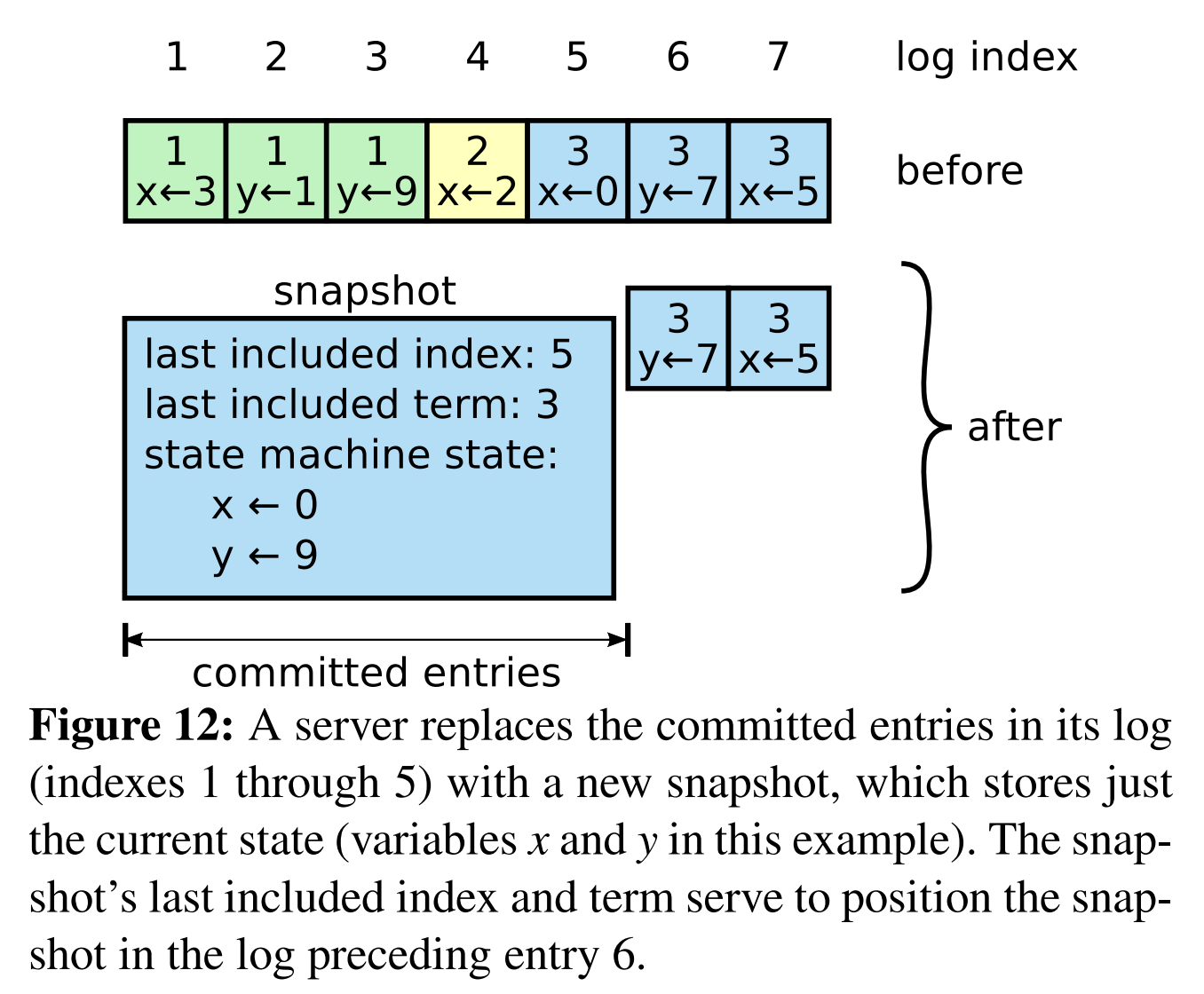
Log Compaction
Log不能无限增长是吧。所以和数据库的checkpoint一样,这里有一个snapshot的概念。
snapshot肯定要把当前状态记录下来;另外,为了配合之前讲的prevIndex式更新,自然还要记录一下该snapshot最后包含的index和term。