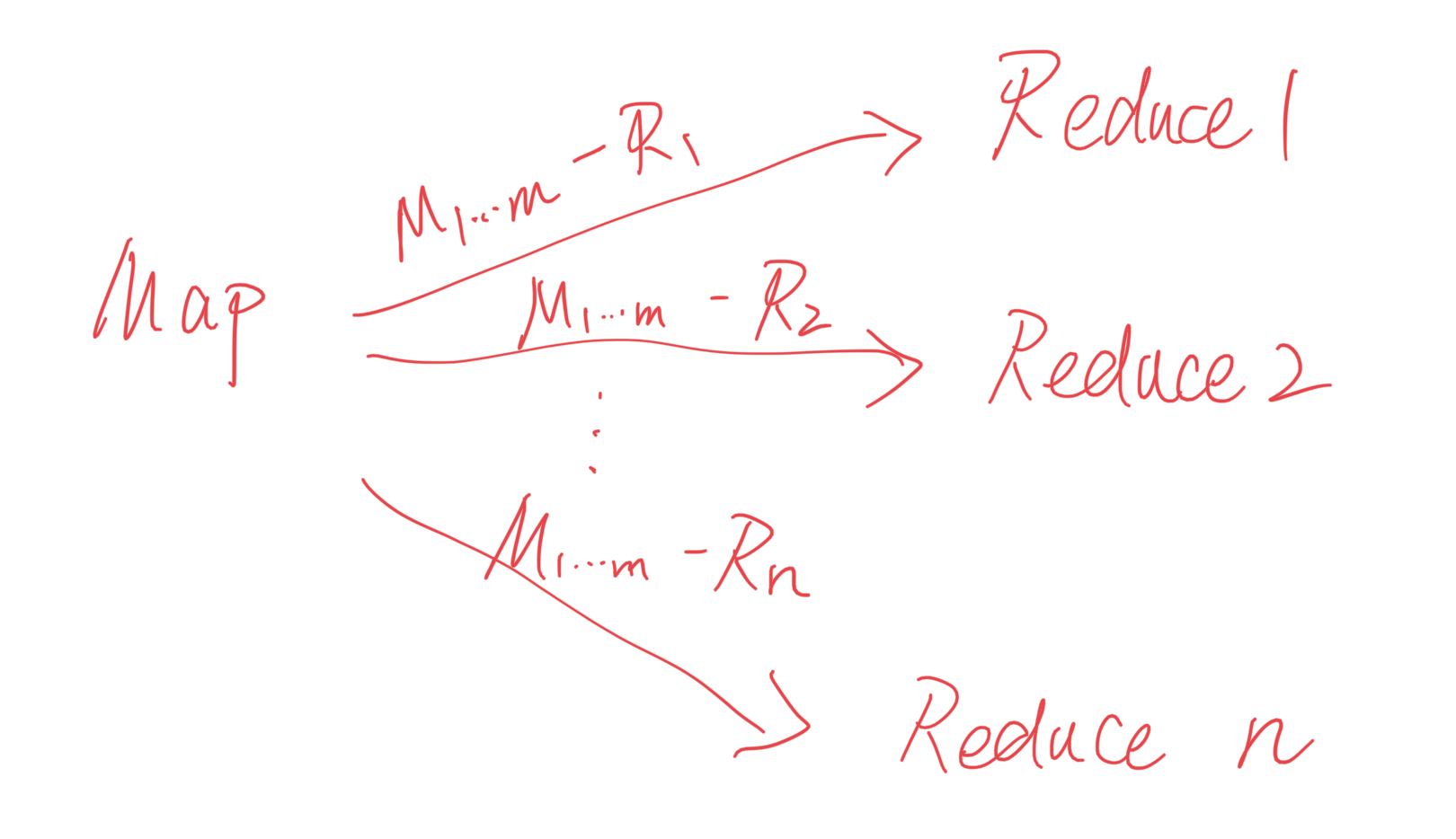
MapReduce是怎么切的
当时学mr的时候有一个地方被卡了挺久,就是怎么分的M个map task和R个reduce task,特别是map完到reduce怎么分的。
我们以paper里的wordcount程序为例…

Map task还是比较好分的,水平切成M份就完事了。
每台机器Map完之后大概就是这么个形态:

然后会根据一个function把这个结果文件切成R份,可以用hash类比:
这里M1指的是第一台Map机器,Ri指的是第i个Reduce partition。

如果我是执行第一个Reduce任务的机器,那我就从每台Map机器上读取对应的R1 partition。因为每个单词只会在一个partition里面,就不会出现一个单词被分到多个reduce服务器的情况。