
浅谈c++优化
本文大部分整理自Optimizing_cpp
绪论
在某次面试中,我被要求写一道算法题。题面是:给一个vector,找出恰好出现两次的元素。
well,这题应该是没有奇技淫巧的。总的来说有两种不错的方法:
方法1. 排序双指针 时间O(nlogn) 空间O(logn)
void solve1(vector<int>& a, vector<int>& res) {
sort(a.begin(), a.end());
int idx = 0;
int cnt = 0;
while (idx < a.size()) {
if (a[idx] == a[idx - 1]) cnt++;
else {
if (cnt == 2) res.push_back(a[idx - 1]);
cnt = 0;
}
idx++;
}
if (cnt == 2) res.push_back(a[idx - 1]);
}
方法2. 哈希表 时间O(n) 空间O(n)
void solve2(vector<int>& a, vector<int>& res) {
unordered_map<int, int> hash;
for (int i : a) {
hash[i]++;
}
for (auto &[k, v] : hash) {
if (v == 2) res.push_back(k);
}
}
分析完时间复杂度,面试官问:
给一个很大的随机vector,实际运行哪个快?
我当然回答O(n)的那个快咯。
结果(1000万个数据,已经开了O3优化):
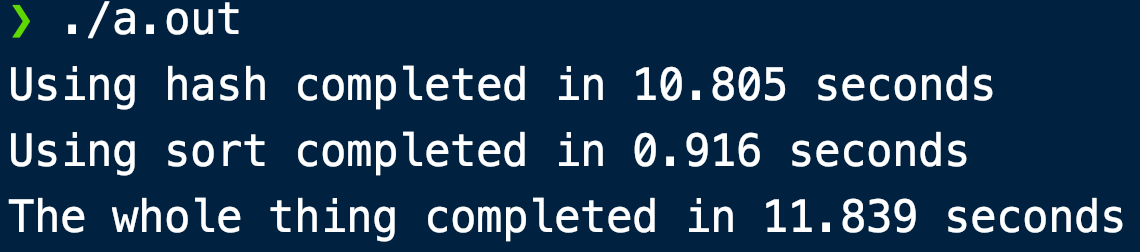
沃超。什么情况。并且应该不是cold cache,调换调用顺序之后结果也一样。
于是我去查了查资料…
优化内存访问
这部分的主旨基本就是“尽量顺序访问内存”。
CppCon 2014: Chandler Carruth “Efficiency with Algorithms, Performance with Data Structures”
这个视频挺有意思的。对于数据结构,演讲者直接说:“只要用vector就行了,其他数据结构都是腊鸡”。
给的理由就是“顺序访问”。他的建议是“永远不要用linked list”。
map的红黑树rebalance巨慢。unordered_map的bucket里还是linked list,所以也巨慢。
另外,书中所说,基本所有STL容器都使用堆上动态分配内存(可以用Allocator参数更改这一行为)。而动态分配内存很慢(后面讲到)。
Latency Numbers Every Programmer Should Know
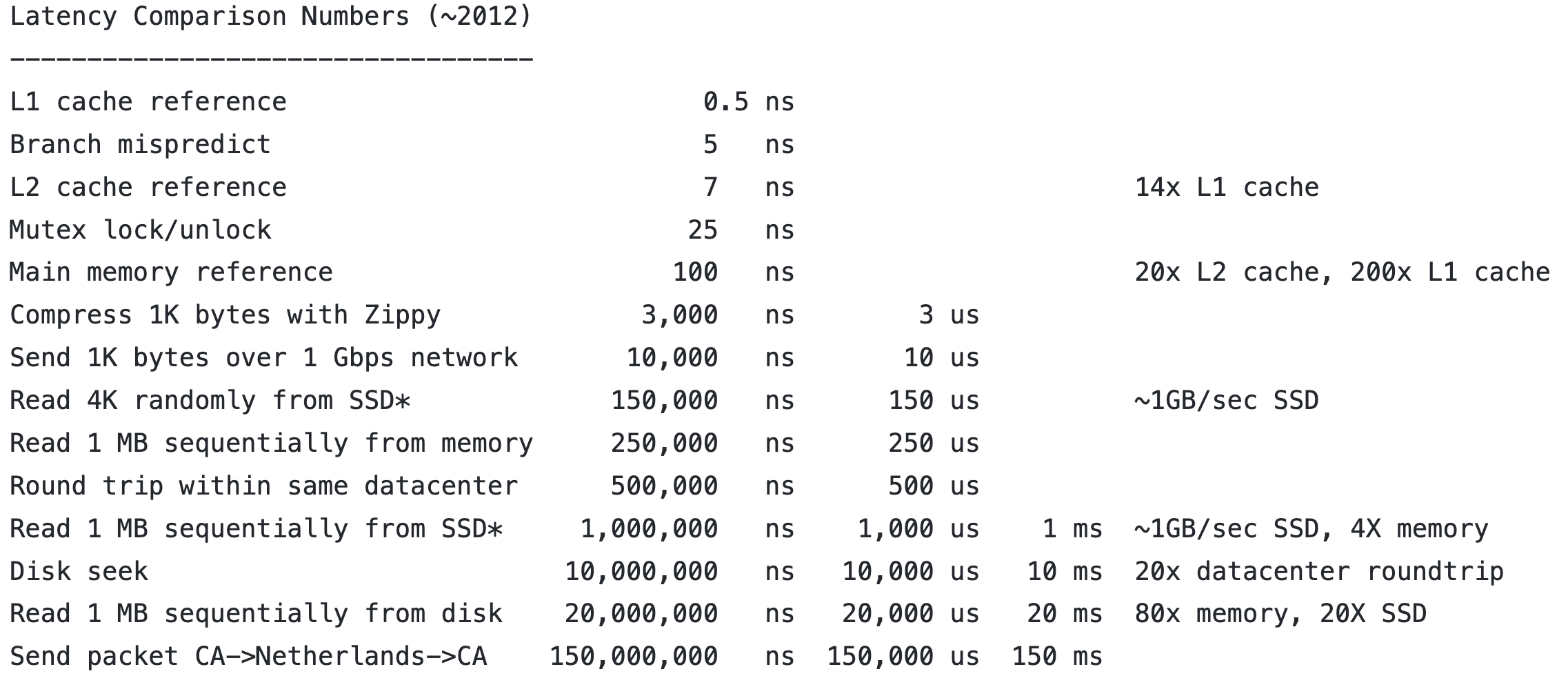
可以看到L1cache和memory之间差了200倍,L2cache和memory之间差了20倍。这或许可以解释为什么绪论中的排序比哈希表快。对于1000万个数据,log2大概是23。实际运行大概比hash快10倍。所以差不多是L1cache与mainmem的差距(200x)。
使用动态分配内存非常耗时间。其原因是heap会变得frgmented,而你无法确定OS的垃圾收集什么时候会发生/会消耗多长时间。
另外,编译器常常无法对指针类型的变量进行优化。因为一个指针指向的地址可能会以另一种形式在代码中存在(pointer aliasing),而编译器无法知道这点,就无法优化了。具体可以看书的80页。
一些情况只能用动态分配,比如运行前不知道array size的情况;太大的对象(超出栈范围,默认一般是1MB)的情况,等等。
PS. 与堆相比,栈上分配变量就好得多,因为就栈那么一块地方翻来覆去用,大部分情况都会在cache里面。
最后也是老生常谈的一点:尽量顺序(内存意义上)访问元素。
经典例子就是二维数组要按行来遍历,不要按列来遍历。
STL容器的一些注意点
vector里面如果储存的是有constructor的对象,vector声明和resize的时候都会调用对象的default constructor。所以小心。
如果提前知道要push_back多少元素,可以先使用reserve(n)来更改vector的capacity。
Out-of-order Execution
CPU是可以多任务同时执行的,但是有的时候CPU无法这么操作。其本质原因是“之后的计算需要依赖之前的计算结果”。一个经典的例子:

另一个经典的例子(循环):

在上面,CPU只能老老实实一个一个加到sum中,无法并行操作。
但通过loop unrolling的技巧,就可以提升两倍的效率:

摘抄书中的总结部分:
