回溯3.
90. 子集 II
和40的套路是一样的:排序+startindex去重。
def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:
res = [[]]
path = []
def helper(nums, startindex):
nonlocal res, path
for i in range(startindex, len(nums)):
if i > startindex and nums[i] == nums[i-1]: continue
path.append(nums[i])
res.append(path.copy())
helper(nums, i+1)
path.pop()
nums = sorted(nums)
helper(nums, 0)
return res
491. 递增子序列
这题几乎一样,但是不能排序了,怎么办?
把题目的意思翻译一下,其实是要求相同父节点下不能有重复。比如[6,7,7],在6之后的,startindex=1的子问题中重复遍历了两次7.这个时候第二个7就要能识别出重复了并跳过,以免出现两个[6,7]。
下图清晰地展示了这个思想。
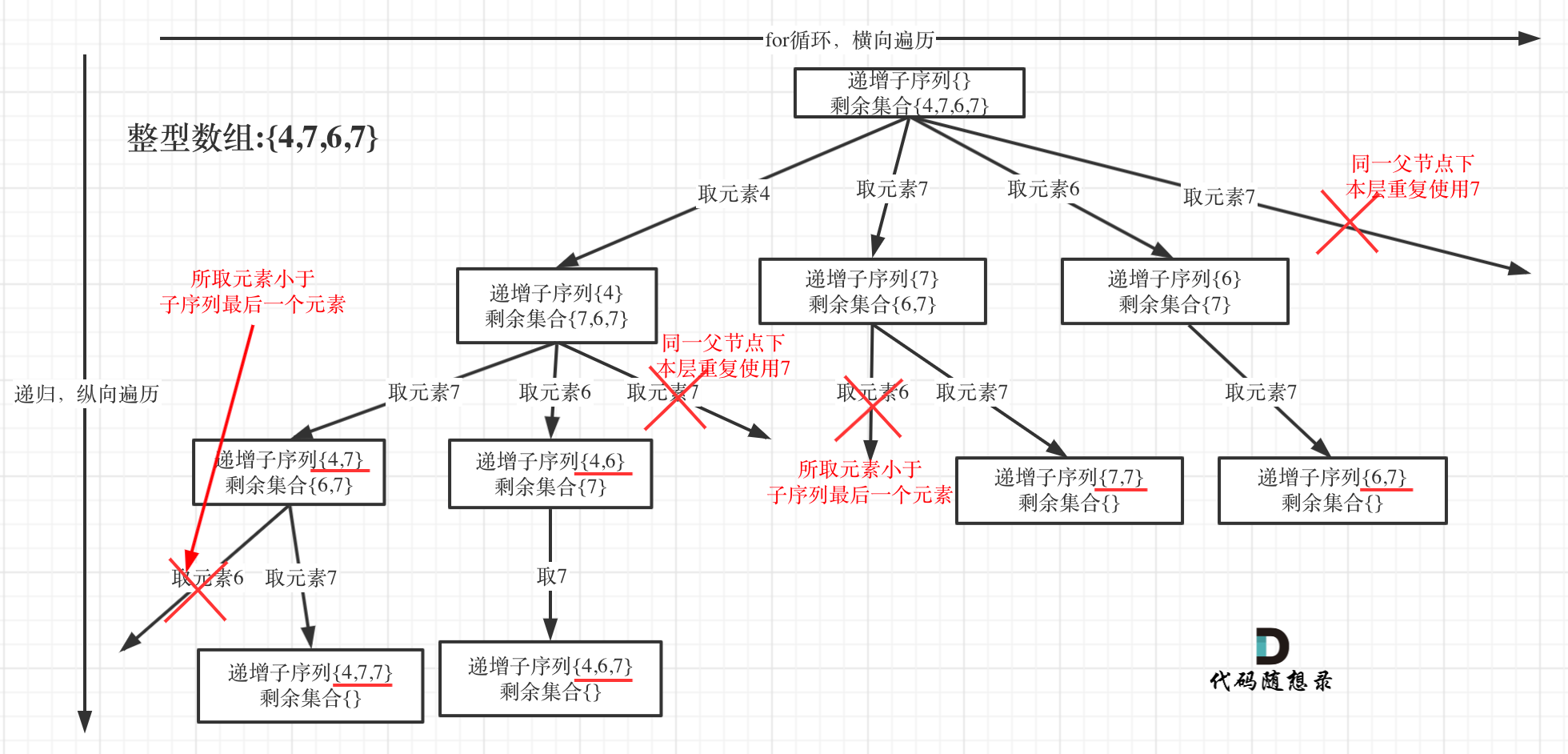
明白了思路,代码就很简单了,在同一个子问题中搞个set去重就好了。
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
res = []
path = []
def helper(nums, startindex):
nonlocal res, path
seen = set()
for i in range(startindex, len(nums)):
if nums[i] in seen:
continue
else:
seen.add(nums[i])
if not path or nums[i] >= path[-1]:
path.append(nums[i])
if len(path) > 1:
res.append(path.copy())
helper(nums, i+1)
path.pop()
helper(nums, 0)
return res
插一句,其实之前几个题也能按照这个方法来做(因为同样是保证同一个子问题中不能重复),但是排序+startindex判断需要的额外空间以及代码行数都比这个要少。
46. 全排列
这题和组合不一样,不能忽略之前处理过的元素。比如[1,2,3],处理完1开头的排列之后,2开头的排列里面还是可以有1. 因此,i的range就是整个数组了。
但是一个树枝中,已经包含的元素不可以再次出现了。比如2开头的排列不能再来一个2. 所以使用一个树枝维度的used数组(bitmap)来追踪哪些index上的数已经使用过了。
def permute(self, nums: List[int]) -> List[List[int]]:
res = []
path = []
def helper(nums, used):
for i in range(len(nums)):
if used[i]: continue
path.append(nums[i]) # symmetry 1
used[i] = 1 # symmetry 2
if len(path) == len(nums):
res.append(path.copy())
else:
helper(nums, used)
used[i] = 0 # symmetry 2
path.pop() # symmetry 1
helper(nums, [0]*len(nums))
return res

47. 全排列 II
经过前两题的历练,这题的要求可以整理为:
- 因为是全排列,所以同一树枝不能有重复。
- 因为输出不能有重复,所以同一子问题中不能有重复。
那么缝合一下就可以了。
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
res = []
path = []
def helper(nums, used):
seen = set()
for i in range(len(nums)):
if used[i]: continue
if nums[i] in seen: continue
seen.add(nums[i])
path.append(nums[i]) # symmetry 1
used[i] = 1 # symmetry 2
if len(path) == len(nums):
res.append(path.copy())
else:
helper(nums, used)
used[i] = 0 # symmetry 2
path.pop() # symmetry 1
helper(nums, [0]*len(nums))
return res
子问题中去重与树层去重是否等价?
先说结论:不一定等价,并且树层去重才是所有类似题目的最终目的,子问题中去重不一定就能树层去重。
之前491中我们用了set对每个子问题中的元素进行了去重。这里子问题去重->树层去重,因为这里重复只可能是path当中相同的元素在不同的位置重复了,比如[4,6,4,6,4]中出现了两个[4,4]。但这里第二个4永远不会作为path的创始成员,因为在第一个4的时候它就被eliminate了。
也提到了之前的组合问题其实也可以用相似的方法。但是需要注意的是组合问题中,因为不同元素不同排列的两个组合也算作重复,所以子问题去重不等于树层去重。如下图所示。
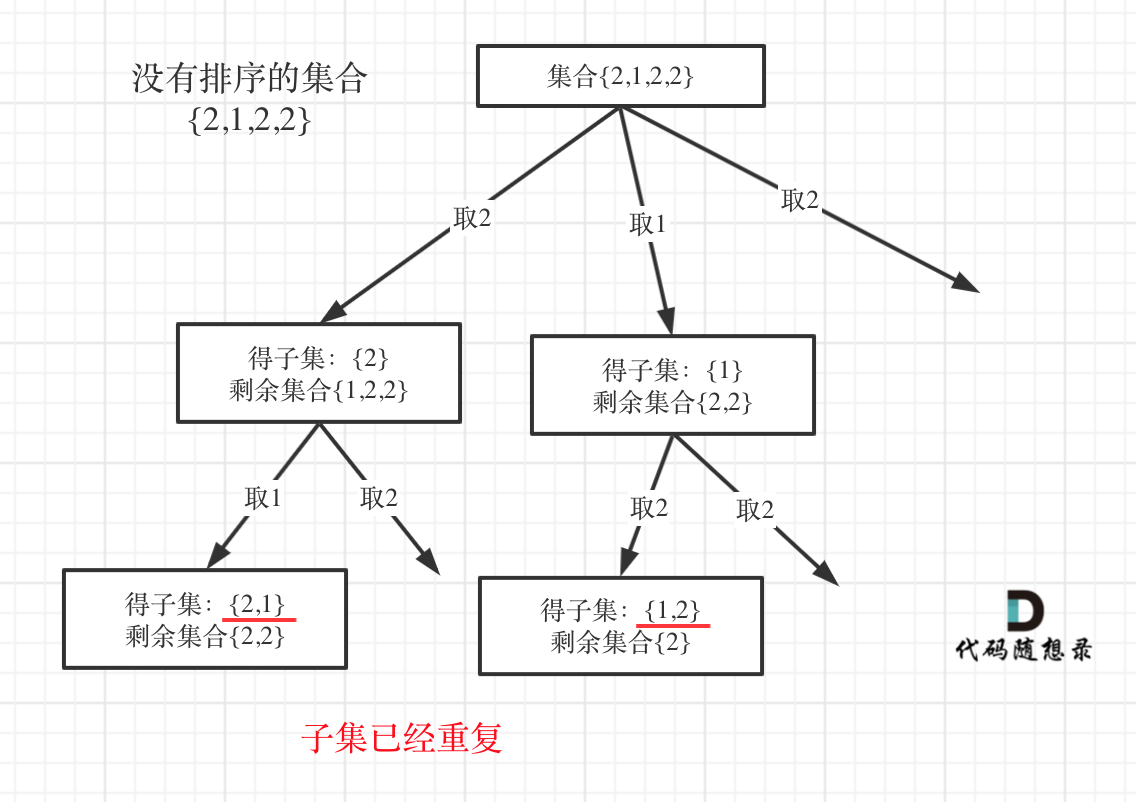
但是组合问题中只要预先排序了,同样是可以用子问题去重的。这是由于遍历从左到右,像上图的[1,2]/[2,1]的情况就自动消失了。
那么为什么全排列中子问题去重->树层去重也成立呢?通过上面两个例子大家应该懂了:因为全排列中的重复和491一样,只可能是path当中相同的元素在不同的位置重复了。
总结:如果重复情况只在path当中相同的元素在不同的位置重复这边出现,那么子问题去重->树层去重。如果path当中不同的元素在不同的位置重复也算重复(就像在组合问题中一样),那就必须先对输入排序。